flyingice.github.io
InnoDB刷脏除了数据库正常关机和系统空闲外还有两个驱动因素:一个是buffer pool空间不够需要从中淘汰数据页,如果被驱逐的页面正好是脏页的话需要先将它刷盘,这种情况对应的是LRU flush;另一个是redo log快要占满,需要推进checkpoint来腾出剩余空间,该情况对应flush list flush。本文只讨论后者的具体实现(贴出的代码非完整片段)及影响因素。
系统参数innodb_io_capacity在很大程度上决定了刷脏的最大IOPS,但是数据库并不是一直保持这个速率满负荷刷脏的。实际速率主要受两个因素影响,buffer pool中当前的脏页比例以及checkpoint年龄,源代码在buf0flu.cc的page_cleaner_flush_pages_recommendation()方法中。后台线程page cleaner是在mysql 5.6中才引入的,之前版本的刷脏操作在用户线程进行。有了page cleaner之后,只有当checkpoint年龄超过同步刷脏点的情况下才会在用户线程中完成,这时候所有其它用户线程都会阻塞来等待刷脏的用户线程。
cur_lsn = log_buffer_dirty_pages_added_up_to_lsn(*log_sys)
time_t curr_time = ut_time();
double time_elapsed = difftime(curr_time, prev_time)
/* How much LSN we have generated since last call. */
lsn_rate = static_cast<lsn_t>(static_cast<double>(cur_lsn - prev_lsn) /
time_elapsed);
lsn_avg_rate = (lsn_avg_rate + lsn_rate) / 2;
page_cleaner_flush_pages_recommendation()先统计redo log产生的速率。prev_lsn, prev_time和lsn_rate都是私有静态变量,保留了上次函数被调用之后的状态。计算lsn_avg_rate的时候并没有直接用lsn差值除以时间的结果,而是用该结果再和之前的lsn_rate做平均,猜测是为了减少redo log生成速率突然变化的影响。另外可以注意到,当redo log的真实产生速率稳定在某个水平的时候,lsn_avg_rate在不断迭代的过程中会无穷趋近于真实速率。
oldest_lsn = buf_pool_get_oldest_modification_approx();
ut_ad(oldest_lsn <= log_get_lsn(*log_sys));
age = cur_lsn > oldest_lsn ? cur_lsn - oldest_lsn : 0;
pct_for_dirty = af_get_pct_for_dirty();
pct_for_lsn = af_get_pct_for_lsn(age);
pct_total = ut_max(pct_for_dirty, pct_for_lsn)
这里是决定刷盘速率的核心逻辑。af_get_pct_for_dirty()和af_get_pct_for_lsn()分别对应了文章开始提到的脏页比例和checkpoint年龄这两个因素,最后pct_total取较大的那个因子。这里pct_for_dirty的取值是一个[0, 100]的整数,而af_get_pct_for_lsn数值是可能超过100的。为了先理清主线把af_get_pct_for_dirty()和af_get_pct_for_lsn()的实现细节放到最后。
lsn_t target_lsn = oldest_lsn + lsn_avg_rate * buf_flush_lsn_scan_factor;
for (ulint i = 0; i < srv_buf_pool_instances; i++) {
buf_pool_t *buf_pool = buf_pool_from_array(i);
ulint pages_for_lsn = 0;
for (buf_page_t *b = UT_LIST_GET_LAST(buf_pool->flush_list); b != NULL;
b = UT_LIST_GET_PREV(list, b)) {
if (b->oldest_modification > target_lsn) {
break;
}
++pages_for_lsn;
}
sum_pages_for_lsn += pages_for_lsn;
}
sum_pages_for_lsn /= buf_flush_lsn_scan_factor;
if (sum_pages_for_lsn < 1) {
sum_pages_for_lsn = 1;
}
ulint pages_for_lsn =
std::min<ulint>(sum_pages_for_lsn, srv_max_io_capacity * 2);
n_pages = (PCT_IO(pct_total) + avg_page_rate + pages_for_lsn) / 3;
然后计算总共要刷的脏页数量。buf_flush_lsn_scan_factor是一个静态常量,值为3,为什么取3不太理解。根据checkpoint位置和redo log速率找到target_lsn作为扫描终止点。然后去每一个buffer pool实例的flush list去找这个目标lsn。
不像LRU list包含所有缓存的数据页(不论干净还是脏),flush list里面只有脏页。换句话说,脏页会同时出现在LRU list和flush list里。但是同一脏页并没有在两个链表里重复存储,这是通过两个链表节点共享同一数据类型做到的。
为了理解这一点,先来看下buffer pool的核心数据结构buf_pool_t,buf_chunk_t,buf_block_t,buf_page_t,它们三者是依次包含的关系。除了buf_chunk_t定义在buf0buf.ic里,其余的都定义在buf0buf.h中。
struct buf_chunk_t {
ulint size; /*!< size of frames[] and blocks[] */
unsigned char *mem; /*!< pointer to the memory area which
was allocated for the frames */
buf_block_t *blocks; /*!< array of buffer control blocks */
};
struct buf_block_t {
buf_page_t page; /*!< page information; this must
be the first field, so that
buf_pool->page_hash can point
to buf_page_t or buf_block_t */
byte *frame; /*!< pointer to buffer frame which
is of size UNIV_PAGE_SIZE, and
aligned to an address divisible by
UNIV_PAGE_SIZE */
};
buffer pool在初始化的时候按照chunk来分配内存,代码参见buf0buf.cc中的buf_pool_init()。如下图所示,每个chunk包含控制块和数据帧,控制块中包含指向对应真实数据的指针。
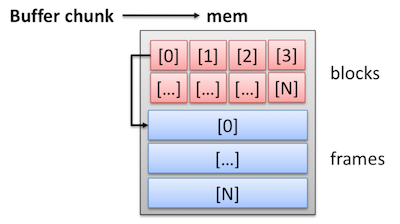
buffer_pool_t结构体对应buffer pool的一个实例(buffer pool总大小超过1GB时会被分割成innodb_buffer_pool_instances个实例),里面维护了与刷盘相关的重要链表LRU和flush list。这两个链表的节点类型都是结构体buf_page_t,buf_page_t内部有两个名称为LRU和list的数据域,分别记录了它在LRU list和flush list中的位置(即指向前后相邻节点的指针)。上面设计中有个值得注意的地方是buf_page_t结构体在buf_block_t中从第一个字节开始存放,这样做可以方便*buf_page_t和 *buf_block_t两种指针类型之间的相互cast。尽管buf_page_t中没有指向数据帧的指针,也可以通过先cast成buf_block_t类型再访问frame指针来得到真实数据。
上面刷脏的具体实现中是在buf_pool->flush_list里从末端开始搜索,原因在与flush list是按照每个数据页的oldest_modification来排序的,最早变成脏页的排在队尾。oldest_modification存储数据页从干净页变成脏页的第一次修改所对应的lsn,之后该数据页的修改只更新newest_modification,oldest_modification保持不变直到刷盘重新置0表示变成干净页。因为flush list的有序性,当搜索到第一个满足oldest_modification > target_lsn条件的页面时就跳出循环,这个时候page cleaner已经收集到了足够多的脏页。最后做PCT_IO(pct_total),avg_page_rate和pages_for_lsn三者的平均得到需要刷盘的页面总数。
现在回到af_get_pct_for_dirty()和af_get_pct_for_lsn()的实现细节。
控制脏页比例有两个重要参数innodb_max_dirty_pages_pct_lwm和innodb_max_dirty_pages_pct。前者是脏页比例低水位,后者是高水位。af_get_pct_for_dirty()的实现里先统计buffer pool中的脏页比例,当低水位未设置的时候,脏页比例在小于高水位之前都不会影响刷盘速率;若设置了低水位且脏页比例大于低水位,则返回100 * 脏页比例 / 高水位。
af_get_pct_for_lsn()的计算涉及innodb_adaptive_flushing,innodb_adaptive_flushing_lwm,innodb_io_capacity以及innodb_io_capacity_max四个可调参数和异步刷脏点max_modified_age_async。max_modified_age_async定义在log0chkp.cc中,值为redo log总容量的7/8。由于同步刷脏仍然在用户线程进行,所以af_get_pct_for_lsn()的计算并不会受到同步刷脏点max_modified_age_sync的影响。具体计算方法:1)若checkpoint年龄比自适应刷脏低水位小则返回0,否则下一步;2)年龄小于异步刷脏点且未开启自适应刷脏时返回0,否则下一步;3) 通过如下启发式算法返回影响因子。
lsn_age_factor = (age * 100) / limit_for_age;
ut_ad(srv_max_io_capacity >= srv_io_capacity);
return (static_cast<ulint>(((srv_max_io_capacity / srv_io_capacity) *
(lsn_age_factor * sqrt((double)lsn_age_factor))) /
7.5));
系统参数innodb_io_capacity的设置受限于硬盘随机写的IOPS,一般不会随意变动。所以如果想加快flush list flush的速度,可以尝试将innodb_io_capacity_max的值调高。
参考资料:
[1] InnoDB adaptive flushing in MySQL 5.6: checkpoint age and io capacity
[2] Different flavors of InnoDB flushing
[3] MySQL 5.6: flushing potential